T-Num – A Highly Customizable Transformer-Based Model for Multivariate Numerical Sequential Data Prediction & Analysis
Introduction
Since Transformer-based language models in general and Large Language Models (LLMs) in particular are designed to accept a sequence of input tokens and predict the next token (or classify a sequence, etc.), it is natural to expect good prediction power for Transformer-based models when dealing with other types of sequential data. In other words they are very powerful conditional probability distribution estimators. However, there are several challenges that need to be addressed before these powerful machines can be used efficiently and effectively with other types of data.
We introduce T-Num – a highly customizable Transformer-based model for specifically working with multivariate numerical sequential data. It is very easy to use T-Num through an API endpoint deployable in AptAI platform. In this article we are going to cover how AptAI’s T-Num API can be used to train a custom T-Num model on a set of numerical sequential data and to be used to make predictions given new data points. Here, we will focus on training the base model for seq2seq predictions – more advanced topics will be covered in the coming articles which will depend on proper configuration and training of the base model. T-Num sets the stage for our exciting novel search algorithm that is currently being developed.
Datasets
We focus on two types of datasets with multiple types of data series (multi-modal datasets in some sense). In the first instance, we have a dataset where a single dataset consists of several types of data series all belonging to the same experiment or environment. For instance, consider the daily average stock prices for multiple companies over the last year.
In the second instance we have a dataset where several multi-modal data series are available. For instance, consider the concentrations of different chemicals in a reaction recorded over the span of several hours. We call this type of data independent experiments dataset.
Preprocessing
The first step towards successful preprocessing and training on a new dataset is to prepare the data in the correct format. Currently, AptAI expects an input CSV file that is formatted as follows:
| Dataset Identifier | Time Step | Data Series (Various Features/Data Types) | ||
| 1 | 1 | 0.5 | 3.1 | 7 |
| 1 | 2 | 6.2 | 3 | 7 |
| 1 | 3 | 9.5 | 6.8 | 9 |
Table 1: In this table, Dataset Identifier identifies a specific experiment, if the series all belong to the same experiment or environment (e.g., stock prices), then they all have the same identifier, otherwise each experiment will have a different identifier. Time Step denotes the progress of time in the data series. Data Series consists of one or several series of different data types. There are no restrictions on the range of data but appropriate quantization methods need to be chosen.
Once the data is prepared – as expected by the platform, AptAI will then pre-process the data and store it in a database locally on your private server and provide you with a unique id (UUID – Universally Unique ID) that you can use to refer to for the next steps.
In the following we have an example code for uploading the formatted data, preprocessing it and obtaining the UUID. This UUID can then be used for the next steps, e.g., training.
Step 1: Uploading the formatted data.
import json
import time
import requests
from PIL import Image
from urllib.parse import urljoin
header = {"x-api-key" : "<YOUR-API-KEY>"}
base_url = "<YOUR-PRIVATE-SERVER-URL>"
## Step 1: Upload your (formatted) training data files(s)
files = [
('file', open('<PATH-TO-YOUR-DATASET>','rb')),
]
url = urljoin(base_url, '/api/v1/upload_files')
r = requests.post(url=url, files=files, headers=header)
if r.status_code != 200:
print("Error uploading file...")
print(r.json())
csv_file_uuids = r.json()['file_uuids']
print("file_uuids:", csv_file_uuids)Step 2: Preprocessing the data (and tracking its progress) to convert it to a T-Num acceptable format (for more details, please refer to the API documentations of the platform).
############
## Preprocessing the data:
payload = {
"input_csv_file_uuids": csv_file_uuids,
# "quant_method": "simple"
}
url = urljoin(base_url, '/api/v1/csv_preprocess')
r = requests.post(url, data=json.dumps(payload), headers=header)
print(r.json())
if r.status_code != 202:
print("Error in preprocess...")
print(r.json())
time.sleep(0.1)
####################
# Track progress for preprocessing
task_uuid = r.json()["task_uuid"]
while 1:
url = urljoin(base_url, '/api/v1/tasks/progress')
values = {"task_uuid": task_uuid}
try:
r = requests.post(url, data=json.dumps(values), headers=header, timeout=1)
print(r.json())
if r.status_code == 200:
if r.json()["progress"] == 100:
time.sleep(1)
break
time.sleep(0.5)
except:
pass
url = urljoin(base_url, '/api/v1/tasks/result')
values = {"task_uuid": task_uuid}
r = requests.post(url, data=json.dumps(values), headers=header)
print(r.json())
processed_data_uuid = r.json()["processed_data_uuid"]
print("processed_data_uuid:", processed_data_uuid)At this point you have the UUID for your processed data and you can move to the next step. It is worth noting that there are additional options for how the data is preprocessed at this step and details can be found in the detailed API documentation that comes with your private server.
Training
The most crucial step in the process of creating a powerful predictive model is of course its training. In order to have a successful training process, one needs to make several decisions regarding the architecture of the model, the learning parameters, and so on. Most of this comes from experience and is sometimes more of an art than science. While in this article we focus on the manual selection of these parameters, the good news is that we are working on an advanced and cutting edge search mechanism that will enable everyone – not just experienced AI experts – to be able to easily design new models and solutions. But for now, we focus on the basic method where these parameters are set manually.
The training can be easily done by providing the processed data UUID to the training API endpoint and the training process will begin.
## Training:
payload = {
'processed_data_uuid': processed_data_uuid,
'batch_size': 10,
'max_iter': 100,
'learning_rate': 1e-4,
'num_head': 4,
'num_embed': 1024,
'num_layer': 5,
'drop_out': 0.1,
'use_half_precision': False,
'validation_split_fraction': 0.2,
'validation_iterations': 10,
'validation_interval_steps': 20,
'max_block_size': 1330
}
url = urljoin(base_url, '/api/v1/train_t_num')
r = requests.post(url, data=json.dumps(payload), headers=header)
print(r.json())
if r.status_code != 202:
print("Error in train...")
print(r.json())
time.sleep(0.1)
####################
# Track progress for Training
task_uuid = r.json()["task_uuid"]
while 1:
url = urljoin(base_url, '/api/v1/tasks/progress')
values = {"task_uuid": task_uuid}
try:
r = requests.post(url, data=json.dumps(values), headers=header, timeout=1)
print(r.json())
if r.status_code == 200:
if r.json()["progress"] == 100:
break
time.sleep(0.5)
except:
pass
time.sleep(5)
url = urljoin(base_url, '/api/v1/tasks/result')
values = {"task_uuid": task_uuid}
while "checkpoint_uuid" not in r.json():
r = requests.post(url, data=json.dumps(values), headers=header)
time.sleep(1)
print(r.json())
checkpoint_uuid = r.json()["checkpoint_uuid"]The result of the training is a UUID for the checkpoint of the trained model that will be used for next steps, e.g. inference, fine tuning, etc.
Inference
Inference can be done in three steps, uploading the initial data to be fed to the model, preprocessing this input data, providing this processed data to the model and retrieving the output. Here is an example:
### Inference:
## Uploadig inputs:
files = [
('file', open('tests/data/metabolomic1input.csv','rb')), # ('file', open('<PATH-TO-YOUR-TRAINING-IMAGE1>','rb')),
]
url = urljoin(base_url, '/api/v1/upload_files')
r = requests.post(url=url, files=files, headers=header)
if r.status_code != 200:
print("Error uploading file...")
print(r.json())
csv_file_uuids = r.json()['file_uuids']
print("file_uuids:", csv_file_uuids)
time.sleep(5)
#####
## Preprocess inputs:
payload = {
"input_csv_file_uuids": csv_file_uuids,
"checkpoint_uuid": checkpoint_uuid
}
url = urljoin(base_url, '/api/v1/csv_preprocess')
r = requests.post(url, data=json.dumps(payload), headers=header)
print(r.json())
if r.status_code != 202:
print("Error in train...")
print(r.json())
time.sleep(0.1)
####################
# Track progress for preprocessing
task_uuid = r.json()["task_uuid"]
while 1:
url = urljoin(base_url, '/api/v1/tasks/progress')
values = {"task_uuid": task_uuid}
try:
r = requests.post(url, data=json.dumps(values), headers=header, timeout=1)
print(r.json())
if r.status_code == 200:
if r.json()["progress"] == 100:
break
time.sleep(0.5)
except:
pass
url = urljoin(base_url, '/api/v1/tasks/result')
values = {"task_uuid": task_uuid}
r = requests.post(url, data=json.dumps(values), headers=header)
print(r.json())
processed_data_uuid = r.json()["processed_data_uuid"]
print("processed_data_uuid:", processed_data_uuid)
## Inference:
payload = {
'checkpoint_uuid': checkpoint_uuid,
'processed_data_uuid': processed_data_uuid,
'max_new_tokens': 400,
'batch_size': 1,
'max_block_size': 400
}
url = urljoin(base_url, '/api/v1/t_num_inference')
r = requests.post(url, data=json.dumps(payload), headers=header)
print(r.json())
if r.status_code != 202:
print("Error in train...")
print(r.json())
time.sleep(0.1)
task_uuid = r.json()["task_uuid"]
while 1:
url = urljoin(base_url, '/api/v1/tasks/progress')
values = {"task_uuid": task_uuid}
try:
r = requests.post(url, data=json.dumps(values), headers=header, timeout=1)
print(r.json())
if r.status_code == 200:
if r.json()["progress"] == 100:
break
time.sleep(0.5)
except:
pass
time.sleep(5)
url = urljoin(base_url, '/api/v1/tasks/result')
values = {"task_uuid": task_uuid}
r = requests.post(url, data=json.dumps(values), headers=header)
print(r.json())
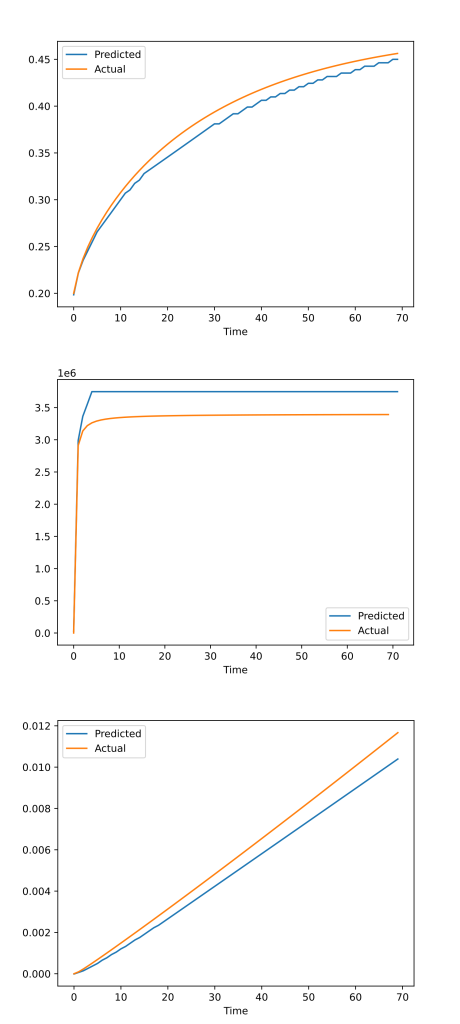
outputs = r.json()['outputs']Sample Results
We tested T-Num on a synthetic dataset (predicting metabolic pathway dynamics from multiomics data – courtesy of the Lawrence Berkeley National Lab) and the results were pretty interesting – even though we did not train the model more than an hour and the input was merely the concentrations of the metabolites only at the initial step! Of course the upcoming search mechanism is expected to make this much more interesting – but these initial results show that our solution has the potential to predict different trends with different ranges in a diverse multi-modal setting!