AptAI-Search: An Efficient RL-Based Search for Transformer-Based Models for Anomaly Detection and Classification of Numerical Patterns
Introduction
As discussed before, since Transformer-based language models in general and Large Language Models (LLMs) in particular are designed to accept a sequence of input tokens and predict the next token (or classify a sequence, etc.), it is natural to expect good prediction power for Transformer-based models when dealing with other types of sequential data. In other words they are very powerful conditional probability distribution estimators. However, there are several challenges that need to be addressed before these powerful machines can be used efficiently and effectively with other types of data.
We introduce AptAI-Search – a Reinforcement Learning based method for searching Transformer-based models for anomaly detection and classification of numerical patterns. In this article we are going to go through the steps for searching this space for a demo of our search method that we are releasing before the full-fledged version. Here, we focus on a publicly available dataset from Kaggle (https://www.kaggle.com/datasets/anushonkar/network-anamoly-detection that we have modified slightly to represent categorical variables with numerical codings – it can be downloaded from this shared Google Drive folder).
The objective is to predict whether a set of network parameters (such as protocol, bytes transferred, duration, etc.) represent an anomaly, i.e., a network attack attempt or they are normal network activities. In our limited experiments we were able to find a model to achieve over %92 within two hours of running the search on a machine with a single 3090 GPU.
Using the Search API
Searching the Model Space
Step1: Uploading the dataset to the server.
import json
import time
import requests
from PIL import Image
from urllib.parse import urljoin
header = {"x-api-key" : "<YOUR-API-KEY>"}
base_url = "<YOUR-PRIVATE-SERVER-URL>"
## Step 1: Upload your (formatted) training data files(s)
files = [
('file', open('<PATH-TO-YOUR-TRAIN-DATASET>','rb')),
('file', open('<PATH-TO-YOUR-TEST-DATASET>','rb')),
]
url = urljoin(base_url, '/api/v1/upload_files')
r = requests.post(url=url, files=files, headers=header)
if r.status_code != 200:
print("Error uploading file...")
print(r.json())
print(r.json())
csv_data_uuid = r.json()['file_uuids'][0]
csv_test_data_uuid = r.json()['file_uuids'][1]
print("csv_data_uuid:", csv_data_uuid)
print("csv_test_data_uuid:", csv_test_data_uuid)Step 2: Start the search process.
payload = {
'data_uuid' : csv_data_uuid,
'test_data_uuid': csv_test_data_uuid,
'data_type': 'csv',
'max_layers' : 4,
'n_head' : [16, 32, 64],
'Dim' : [512, 1024, 2048],
'FC' : [1024,512,2048],
}
url = urljoin(base_url, '/api/v1/search/start')
r = requests.post(url, data=json.dumps(payload), headers=header)
print(r.json())
if r.status_code != 202:
print("Error in search...")
print(r.json())
task_uuid = r.json()["task_uuid"]
time.sleep(5)Step 3: Track progress for the search and view interim results
while 1:
url = urljoin(base_url, '/api/v1/search/status')
values = {"task_uuid": task_uuid}
try:
r = requests.post(url, data=json.dumps(values), headers=header, timeout=1)
print(r.json())
if r.status_code == 200:
r_json = r.json()
if 'results' in r_json:
print("Results:", r_json["results"])
if r_json["progress"] == 100:
break
time.sleep(10)
except:
pass
time.sleep(10)
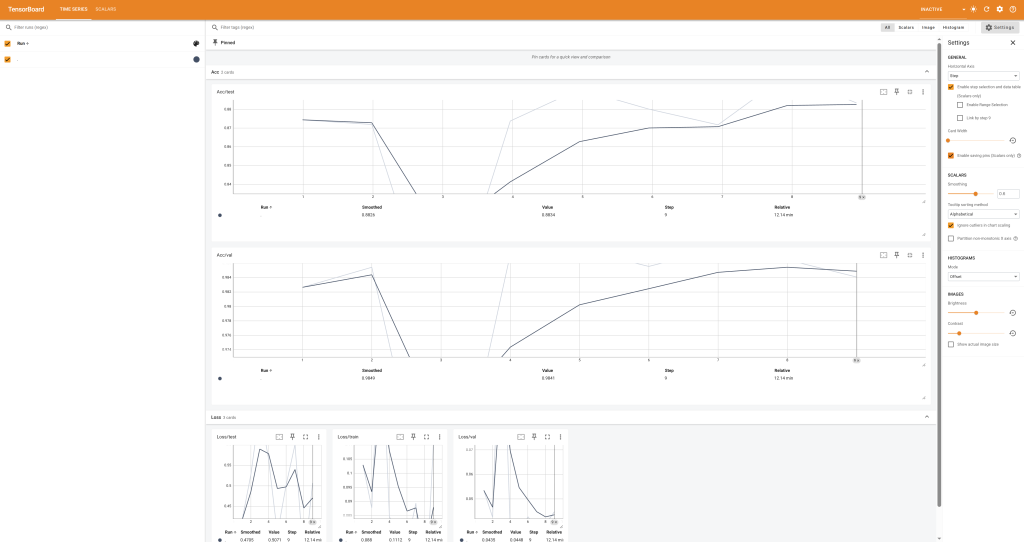
time.sleep(5)You can also use the provided link to Tensorboard with status reports to track the progress.
Inference
Step 1: Upload your inference data (unlabled)
import json
import time
import requests
from PIL import Image
from urllib.parse import urljoin
header = {"x-api-key" : "<YOUR-API-KEY>"}
base_url = "<YOUR-PRIVATE-SERVER-URL>"
## Step 1: Upload your inference data
files = [
('file', open('<PATH-TO-YOUR-INFERENCE-DATASET>','rb')),
]
url = urljoin(base_url, '/api/v1/upload_files')
r = requests.post(url=url, files=files, headers=header)
if r.status_code != 200:
print("Error uploading file...")
print(r.json())
print(r.json())
csv_data_uuid = r.json()['file_uuids'][0]
csv_test_data_uuid = r.json()['file_uuids'][1]
print("csv_data_uuid:", csv_data_uuid)
print("csv_test_data_uuid:", csv_test_data_uuid)Step 2: Inference (choose your desired model from the previous step and replace it with the model used in the following payload).
payload = {
'data_uuid' : csv_data_uuid,
'data_type': 'csv',
"params_string": json.dumps([[64, 64, 64], [1024, 512, 1024], [512, 1024, 512]])
}
url = urljoin(base_url, '/api/v1/inference')
print ("before search is called")
r = requests.post(url, data=json.dumps(payload), headers=header)
print(r.json())