The era of specialized visual intelligence using fine-tuned and aligned foundation models has begun.
Every week, another AI agent framework launches with impressive demos: booking flights, writing code, browsing the web. But there is a critical gap that the industry keeps ignoring. When these agents encounter real-world visual data — an X-ray with a subtle fracture line, a hairline crack on a turbine blade, a mislabeled price tag on a retail shelf — they fail. Not because the underlying architecture is wrong, but because general-purpose vision-language models were never trained to see what domain experts see.
AptAI-VL is a production-grade fine-tuning platform built to close that gap. It transforms frontier vision-language models into domain-specific visual reasoning engines — the kind that agentic systems actually need to operate reliably in high-stakes environments.
The Agentic Bottleneck Nobody Talks About
Consider a modern agentic workflow in clinical diagnostics. The agent receives a patient submission: five chest X-rays from different angles, lab results, and a clinical history. A general-purpose VLM can describe what it sees — "a chest X-ray showing lung tissue," "an area of increased opacity." But a radiologist needs something fundamentally different:
- Is this infiltrate indicative of pneumonia or pulmonary edema?
- Does the opacity pattern suggest bacterial or viral etiology?
- Is the pleural effusion acute or chronic?
- What is the severity grade — mild, moderate, or requiring immediate intervention?
These are not caption-generation problems. They are domain reasoning problems that require the model to have internalized thousands of labeled examples from actual clinical cases, annotated by actual radiologists. No amount of prompt engineering on a base model will reliably produce this level of specificity.
This is the bottleneck. Agentic systems are only as intelligent as the tools they invoke. And when the tool is a vision model that cannot distinguish between benign findings and pathological changes, the entire diagnostic chain collapses.
What AptAI-VL Actually Does
AptAI-VL is a full-stack fine-tuning and deployment platform for vision-language models. It is not a wrapper around an API. It is not a notebook with training scripts. It is an integrated system that takes you from raw domain images to a deployed, inference-ready model with specialized visual understanding.
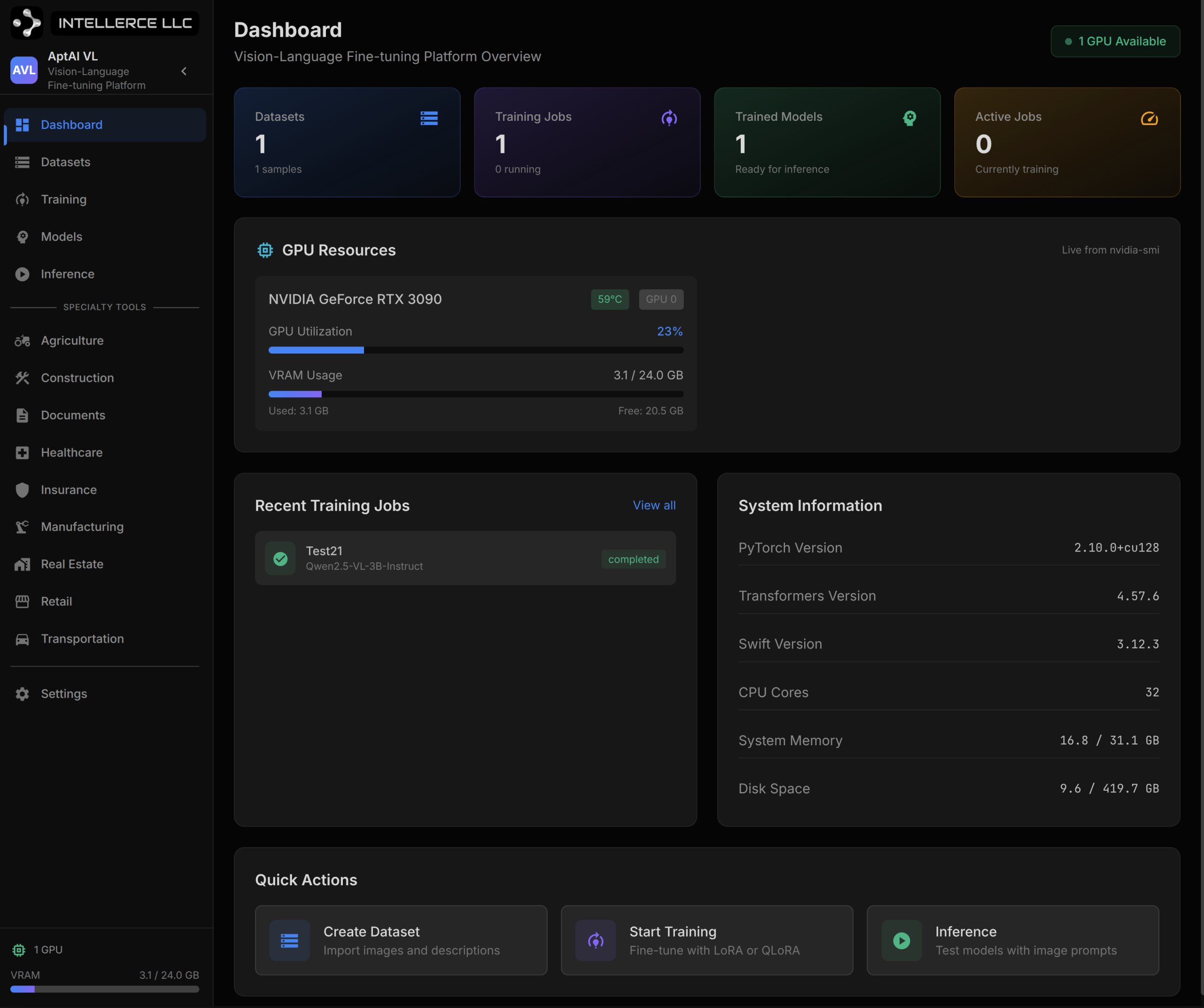
The Architecture
The platform runs a React frontend backed by a FastAPI async backend, with direct GPU orchestration for training and inference. The stack is designed for practitioners who need to iterate fast without fighting infrastructure:
Data Pipeline. Upload domain images individually or in bulk. Annotate with structured metadata — claim type, severity grade, property classification, crop species, document category. The platform validates dataset integrity, handles train/validation splits, and exports in the formats that modern training frameworks expect.
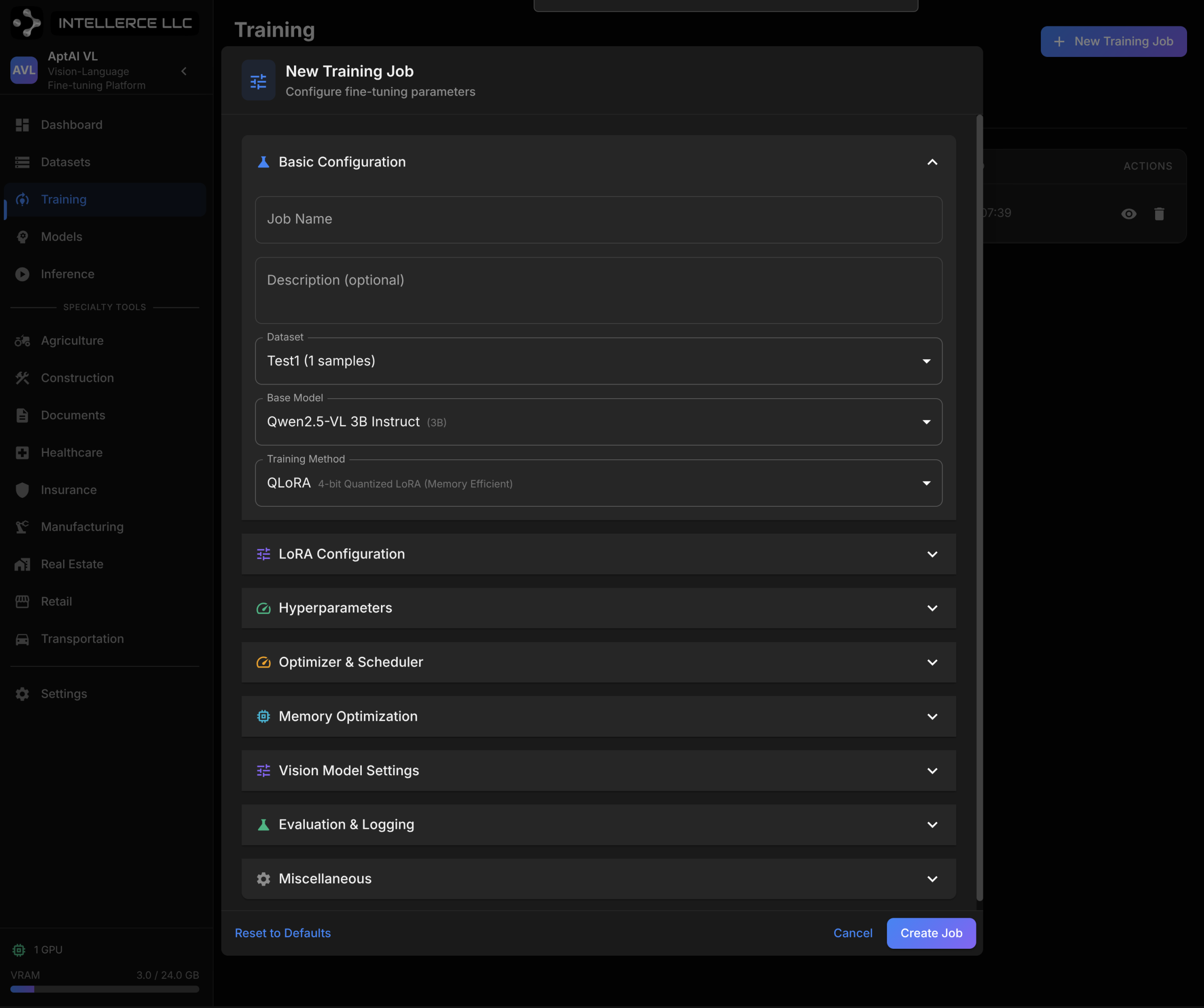
Training Engine. AptAI-VL supports the full Qwen vision-language model family — from the 2B-parameter Qwen3-VL for edge deployment up to the 235B-parameter MoE flagship for maximum capability. Training methods include LoRA, QLoRA (4-bit quantized adaptation), and full fine-tuning. The platform manages GPU memory allocation, gradient accumulation scheduling, checkpoint management, and real-time training metrics.
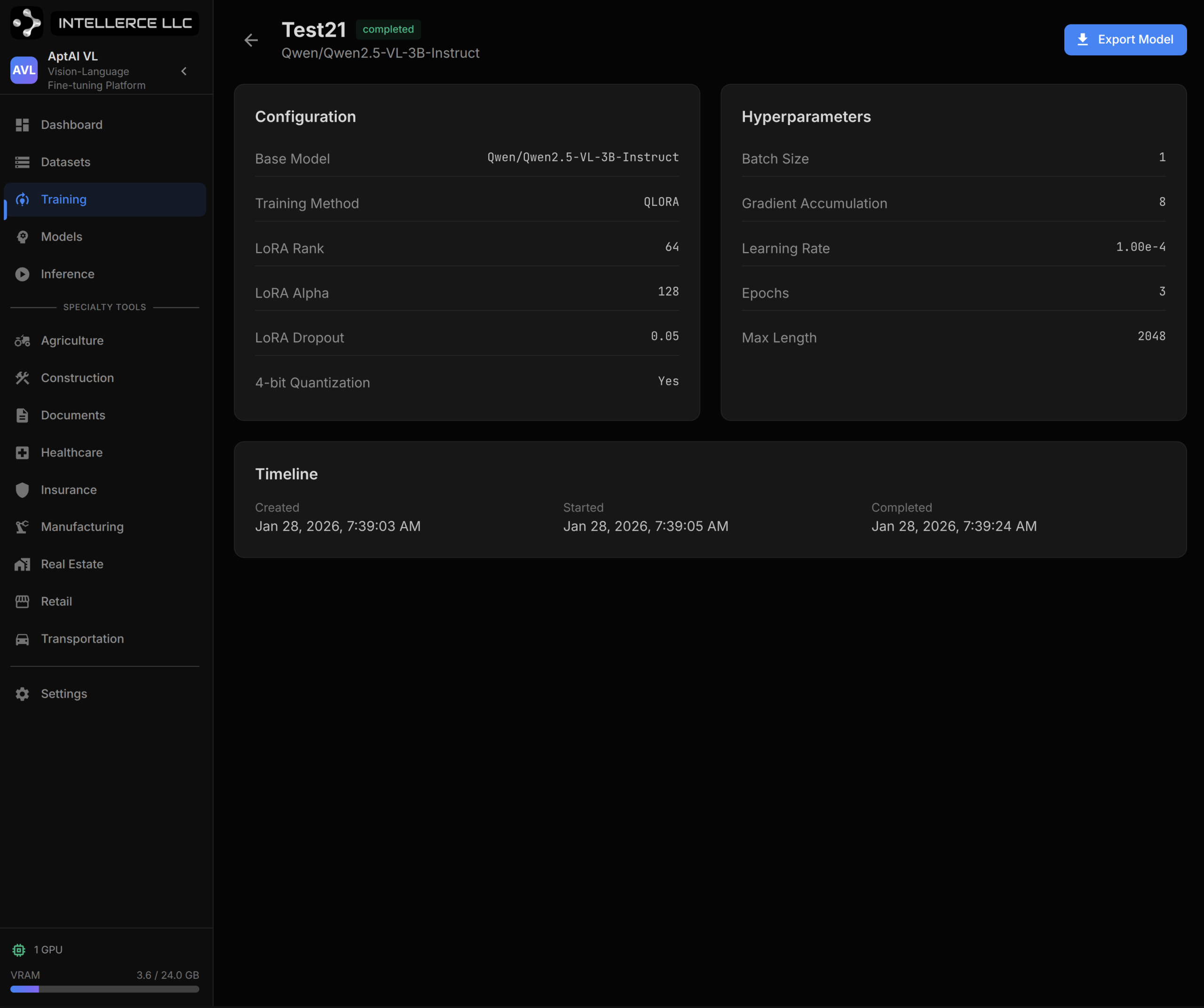
Inference and Evaluation. Load any fine-tuned model — base weights plus adapter — and run inference immediately. Upload a test image, select a prompt template, and evaluate output quality. The platform tracks generation metrics: tokens produced, latency, and model configuration.
Specialty Tools. The system ships with nine domain-specific analysis interfaces, each designed around the actual workflows of professionals in that field.
The Specialty Tool Architecture
Each specialty tool is more than a UI skin over a generic prompt. It is a structured analysis pipeline with:
- Domain-specific system prompts engineered for the target profession's reasoning patterns
- Analysis type taxonomies that map to real-world assessment categories (not generic labels)
- Configurable context parameters — facility type, industry classification, property category, crop species — that condition the model's output distribution
- Structured output formats supporting both human-readable reports and machine-parseable JSON for downstream agent consumption
- Seeded prompt templates that encode domain expertise into reproducible assessment frameworks
Each domain supports batch processing for high-volume production use cases and maintains a local analysis history for iterative refinement.
Why This Matters for Agentic AI
The trajectory of AI agent development is clear: agents will increasingly operate in specialized professional domains. A construction safety agent needs to look at a job site photo and identify that a worker on scaffolding lacks a harness. A precision agriculture agent needs to distinguish between nitrogen deficiency and early-stage fungal infection from a drone image of a wheat field. A retail operations agent needs to read a shelf image and determine that SKU #4471 is out of stock in aisle 7.
These are not hypothetical scenarios. They are active areas of investment across every major industry. And they all share the same dependency: a vision model that has been fine-tuned on domain-specific data to produce domain-specific reasoning.
The Tool-Use Paradigm
In modern agent architectures — whether built on ReAct, function-calling, or more sophisticated planning frameworks — the agent selects and invokes tools based on the current task context. A vision analysis tool is one of the most powerful instruments an agent can wield, but only if that tool produces outputs the agent can reason over reliably.
When an agent calls a fine-tuned medical imaging model through AptAI-VL's structured JSON output format, it receives:
{
"finding_type": "pulmonary_infiltrate",
"severity": "moderate",
"confidence": 0.94,
"affected_regions": ["right_lower_lobe", "right_middle_lobe"],
"observations": [
"Consolidation pattern consistent with bacterial pneumonia",
"No evidence of pleural effusion or pneumothorax",
"Clear costophrenic angles bilaterally"
],
"recommended_actions": [
"Initiate broad-spectrum antibiotic therapy",
"Follow-up chest X-ray in 48-72 hours",
"Monitor oxygen saturation and respiratory status"
],
"clinical_priority": "moderate"
}This is not a caption. This is structured domain intelligence that an agentic system can route, aggregate, cross-reference against clinical guidelines, and use to generate an actionable diagnostic decision.
The Compounding Effect of Specialization
Domain-specific fine-tuning does not just improve accuracy on known tasks. It fundamentally changes what tasks become possible. A base Qwen3-VL model cannot reliably grade diabetic retinopathy severity from a fundus photograph. But a model fine-tuned on 10,000 graded retinal images — annotated by ophthalmologists using the International Clinical Diabetic Retinopathy scale — can. And once that capability exists as a tool, an agentic healthcare system can do something it could never do before: screen patients at scale, flag high-risk cases for specialist review, and track disease progression over time from sequential imaging.
The Model Spectrum: Matching Capability to Constraint
AptAI-VL supports the full spectrum of Qwen vision-language models, and the choice of base model is itself a strategic decision:
- Qwen3-VL-2B — 8 GB VRAM. Deploy on edge devices. A fine-tuned 2B model running on an NVIDIA Jetson at a construction site entrance can perform real-time PPE compliance checks faster than any cloud round-trip allows.
- Qwen3-VL-8B — 20 GB VRAM. The workhorse. Fits on a single consumer GPU for fine-tuning with QLoRA. Strong enough for most domain tasks.
- Qwen3-VL-30B-A3B MoE — 24 GB VRAM. The efficiency play. A mixture-of-experts architecture that activates only 3B parameters per inference pass while drawing on 30B parameters of learned capacity.
- Qwen3-VL-235B-A22B MoE — The ceiling. When the domain is complex enough — histopathology grading, multi-system structural assessment — and accuracy directly maps to financial or clinical outcomes, this is the model that sets the benchmark.
From Platform to Production
AptAI-VL is not the agent. It is the forge where the agent's eyes are sharpened. The workflow is straightforward:
- Curate domain-specific image datasets with structured annotations
- Fine-tune on the appropriate base model using parameter-efficient methods
- Evaluate using the specialty tool interface with real-world test cases
- Iterate on data quality, prompt templates, and training configuration
- Deploy the fine-tuned model as a tool endpoint that any agent framework can invoke
The Larger Thesis
The AI industry is converging on a realization: general intelligence is not general competence. A model that can discuss Rembrandt and solve differential equations may still fail to notice that a weld bead has insufficient penetration or that a crop's chlorosis pattern indicates potassium deficiency rather than iron deficiency.
Agentic systems will be defined not by the reasoning capability of their orchestration layer, but by the precision of their perception tools. AptAI-VL exists because this work — the painstaking curation, training, and evaluation of domain-specific vision models — should not require a machine learning team. It should require domain expertise and a platform that translates that expertise into model capability.
The agents are coming. The question is whether they will see clearly enough to be trusted.
AptAI-VL is developed by INTELLERCE. The platform currently supports the full Qwen2.5-VL and Qwen3-VL model families with LoRA, QLoRA, and full fine-tuning across nine professional domains.


